One thing I’ve been considering lately is what kind of intelligence you could gain from scraping a blog and analyzing the data. To test this out, this is the first in a series of posts where I’ll scrape a blog and try to squeeze out every last bit of useful or interesting intelligence I possibly can.
I’ll start off simple, but down the road I plan to use more advanced techniques in machine learning and natural language processing techniques to see what additional information these tools can uncover. I’m keeping all my analysis on a Jupyter notebook you can find on Github here.
The target site I’ll be using for my analysis is my all-time favourite blog: Marginal Revolution. I have been following this blog pretty much daily since 2005 when I started my undergraduate degree. It’s run by the economists Tyler Cowen and Alex Tabarrok, who are personal heroes of mine.
Why scrape a blog?
For me, scraping Marginal Revolution was just something I did for kicks. Since I’m so interested in the content of the blog, I want to be able to do very customized searches of blog posts that would not be possible through the blog’s built-in search feature.
But there are reasons other than “just for fun” that you might want to scrape a blog. For example, maybe the blog is a competitor or in an industry you’re researching. Maybe you want to find out:
- Roughly how many people read / comment on the blog
- Blogging strategy in terms of number, type, and timing of posts
- Which types of posts produce the most discussion / comments / controversy
- What notable people read the blog (i.e. seeing if they comment in the comments section)
- Analyzing trends over time to determine if things have changed
…and I’m sure there are more possibilities.
Very brief overview of how the scraper works
My goal with the scraper was to get each individual post from the Marginal Revolution website. Marginal Revolution was fairly easy to scrape since the list of posts by month provided a predictable URL structure that made it possible to gather the links for each individual post across the entire website. With the full list of links, it was then simply a matter of making a request to each of these URLs and saving the resulting blog post HTML to disk. The scraper ultimately gathered 23,342 posts.
The final step was to extract the information of relevance through each HTML file and conduct data cleaning. I did this with the python BeautifulSoup library to parse the html and then pandas to do some further data cleaning and feature generation. The final result was a nice csv file:
My scraper had a generous delay between requests so I didn’t create a burden on the website. As you would expect, the scraper took a very long time to run to get all the posts – I ran it slowly over a period of about 3 weeks.
Initial Analysis
Often times when reading Marginal Revolution, I would want to search in ways that the built-in search feature wouldn’t allow. For example, I know that Marginal Revolution has had a few guest posts over the years, but they are difficult to find with the search feature because of the sheer volume of posts. Also, many people guest posting are often mentioned in the regular daily posts by Tyler and Alex, further complicating the search.
With all the posts scraped, figuring out who has all posted on the site and how many posts they’ve done was easy:
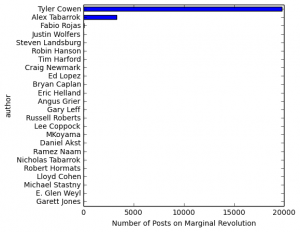
Obviously it’s totally dominated by Tyler Cowen and Alex Tabarrok, as any reader of the blog would expect, but the plot reveals some interesting authors that I had no idea posted on Marginal Revolution.
Now, say I want to look at all the posts by Tim Harford. It’s just a simple filter operation to get all the links and check them out (15 of them):
http://marginalrevolution.com/marginalrevolution/2005/07/dear_economist_-2.html
http://marginalrevolution.com/marginalrevolution/2005/07/using_cartoons_.html
http://marginalrevolution.com/marginalrevolution/2005/07/marginal_revolu-2.html
http://marginalrevolution.com/marginalrevolution/2005/07/we_shall_see_ho.html
http://marginalrevolution.com/marginalrevolution/2005/07/markets_in_ever_6-2.html
http://marginalrevolution.com/marginalrevolution/2005/12/seasonal_advice.html
http://marginalrevolution.com/marginalrevolution/2005/12/seasonal_advice_2.html
http://marginalrevolution.com/marginalrevolution/2005/07/john_kay_on_cli.html
http://marginalrevolution.com/marginalrevolution/2005/12/seasonal_advice_1.html
http://marginalrevolution.com/marginalrevolution/2005/07/choosing_whethe.html
http://marginalrevolution.com/marginalrevolution/2005/07/what_is_the_rig-2.html
http://marginalrevolution.com/marginalrevolution/2005/07/a_critic_on_cri.html
http://marginalrevolution.com/marginalrevolution/2005/07/red_tape_and_ho.html
http://marginalrevolution.com/marginalrevolution/2005/07/should_londoner.html
http://marginalrevolution.com/marginalrevolution/2005/07/risky_business_1.html
I also looked at the amount of discussion generated by each author:
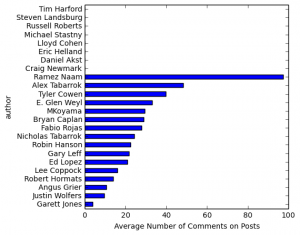
Note that some of these authors only posted once or twice which would skew their results. Also, some posted in the blog’s early years where there appear to be few comments (e.g. Tim Harford in 2005). Interesting to see that Alex’s posts on average seem to generate slightly more comments. Of course, the total amount of discussion / engagement is way higher for Tyler, given that he posts about 5 times as much as Alex.
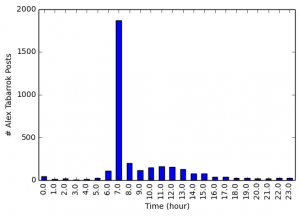
Another easy thing to do is examine the time of post to get an idea of the blogging habits of each of the authors. Each blog post includes the time of publication down to the minute.
Looking at the time of the post reveals some clear patterns. Tyler Cowen is most likely to post in the morning, around 7 am, although he is also likely to post in the early afternoon.
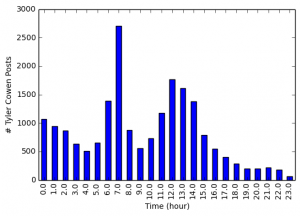
Alex Tabarrok clearly has a much more rigid blogging schedule. Almost all of his posts are published around 7 am.
You can also get an idea of the writing techniques and writing habits of the blog authors. I’m barely scratching the surface of what’s possible here, but as a start I simply looked at the number of characters in the headline. The headline is the most important part of a blog post as it determines whether the reader will continue to read.
The longest headline in Marginal Revolution is 117 characters: “The Icelandic Stock Exchange fell by 76% in early trading as it re-opened after closing for two days last week.” The table below shows the different average headline length for each of the blog authors. Tyler tends to use longer headlines than Alex.
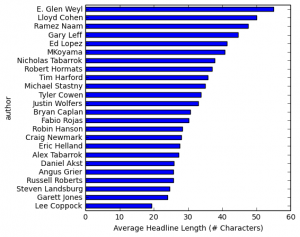
Interestingly, when I read through the top 10 longest headlines, I noticed one called: “Browse every book hyperlink ever posted on Marginal Revolution (is this the second best website ever?)” Clearly I’m not the first person to have scraped Marginal Revolution!
My goal now is to figure out what to do with this data to make the 3rd best website ever…
Addendum: In the comments, the creator of Marginal Revolution Books points to the github repository for his website.
For access to my shared Anki deck and Roam Research notes knowledge base as well as regular updates on tips and ideas about spaced repetition and improving your learning productivity, join "Download Mark's Brain".
hey, here’s the code i used to make MR books https://github.com/LinuxFan2718/marginalrevolutionbooks
Awesome, the one and only MR books guy! Great site, and thanks for the link, I’ll add it to the post.
What a beautiful exchange here in the comments.
The results are interesting, but not very useful for me personally. Coincidentally you shared an example of what I consider to be the main issue. You only randomly discovered that somebody else had scraped the blog.
A few months ago I learned that there’s a biology professor by the name of PZ Myers who has a blog with over 25,000 entries. The entries aren’t equally relevant to your interests, how do you find the most relevant entries? I doubt that you’re going to read all the entries… so do you conduct keyword searches? Ideally you’d simply tell your advanced AI assistant, who sounds (and looks?) like Scarlett Johansson, to sort all the entries according to their relevance to your interests.
Thanks to MR I learned of Paul Romer’s blog entry about Jupyter versus Mathematica, which linked to a great Atlantic article, which linked to Eric S. Raymond’s excellent essay “The Cathedral and the Bazaar”. Naturally I really like the idea of all MR readers having the opportunity to help organize all the MR info.
My coder is trying to persuade me to move to .net from PHP.I have always disliked the idea becauseof the expenses. But he’s tryiong none the less.I’ve been using WordPress on various websites for about ayear and am anxious about switching to another platform.I have heard great things about blogengine.net.Is there a way I can transfer all my wordpress content into it?Any help would be greatly appreciated!