Testing is an important part of development, including developing web applications. Among other benefits, they increase your confidence that your web application is doing what you expect, and a provide a basis for preventing bugs in an automated way when you make changes to your code.
Since testing is such an integral part of web application maintenance and deployment, in this Part 3 of our app-deploy project we’ll put in some basic tests to see how they can be implemented in flask applications and so we will eventually see how tests fit into the deployment workflow. We’ll be using the pytest python library as our testing framework.
To follow along, you can clone the repository:
git clone https://github.com/marknagelberg/app-deploy.git
And then go to the appropriate location in the code with the following command which includes all of the changes made in this post:
git checkout ed2ed02f8b3db
Finally, create the python environment with:
conda env create -f environment.yml
First, a Slight Upgrade to our App
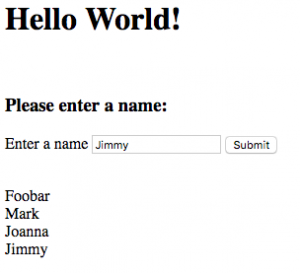
Right now, when out user enters information into the app’s simple web form, the data is simply added to the database and nothing changes from the user’s perspective. To make testing a bit more interesting, we first add a little bit of additional functionality: our app will now print out a list of all the existing names in the database on the main page.
First we add a few lines to app/app.py so that it queries the database to get all names, and then sends the list of names to the template.
https://gist.github.com/marknagelberg/f4cb543ca596d383362ef9383b03ee6a
Then, we update the template to print out these names.
https://gist.github.com/marknagelberg/5b2237cc9157bdbe84b9b3283d0ba133
Now, when you enter in new names, they are listed out for you, like so:
Pytest Installation and Set-up
To start off, let’s activate our app’s conda environment and install pytest:
source activate app-deploy conda install pytest
Our tests will be stored in a top level directory in a folder that we’ll call `tests`. Our tests will be stored in *.py files within this folder. These files must either be named like test_*.py or *_test.py: this is how you tell pytest that these files represent tests (in other words, this is how pytest does “test discovery”).
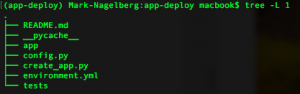
As a reminder, your top level directory should look something like this:
So, let’s add a file called test_app.py in /test.
touch test/test_app.py
To run your tests, you simply just have to enter ‘pytest’ in the command line as follows. No tests have been added to test_app.py yet, so when you run ‘pytest’ now, the result should look like this:

A couple of other small preliminaries to get testing set up:
- Set WTF_CSRF_ENABLED configuration variable equal to False in the testing configuration found in config.py. This is required for tests to run properly. Keep in mind that you normally want to have this set equal to True when you’re running your application in production, since this protects your forms against Cross Site Request Forgery (CSRF) attacks.
- Add __init__.py in your /tests directory.
Adding Tests
The great thing about pytest is that it allows you to write tests in a very concise, pythonic way using assert statements. Suppose you have the following file which defines a function that takes the square of a number. You want to test this. Adding a couple of tests is as easy as this:
https://gist.github.com/marknagelberg/aa99d1be3dca7149c12f0be984a0542a
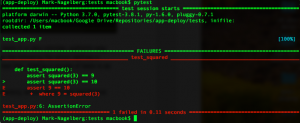
Then, you run your tests by typing `pytest` in the command line when you’re in the app’s main directory. This returns the following result (one test pass, one test fail):
Another great feature of pytest is the ability to produce “fixtures”, which provides tests with pre-initialized objects you require to run your tests. In our case, a great use of fixtures is initializing the test database or the test application instance.
Pytest fixtures have some advantages over the usual setup and teardown functions used in other testing frameworks. One is the ability to run fixtures using different “scopes”, allowing you to do the setup / teardown operation at different times when you run your test to maximize test efficiency. The options for scope here include function, class, module, and session. So, for example, a fixture in the function scope means that the fixture object is invoked once for each test function you define in pytest.
So, say all your tests need to be able to access the Flask test client application instance. Using the module fixture, the application instance is only created once at the very beginning when you run your test, rather than being created and destroyed once for every test function.
For our small app, we’ll create 3 fixtures:
- A database record in our Name table
- The Flask application instance
- The test database
The following code creates a fixture for one database record in our Name table which will make this object available to all our tests.
https://gist.github.com/marknagelberg/c7d5c71bd8e35c452939ba2192910aec
As you can see, you register fixtures using the pytest.fixtures decorator. This function returns the fixture object that you want your tests to access. You access this fixture object in your tests by supplying them as an argument to the test function. The code below shows a test we can add to test_app.py that accesses the new_name fixture and ensures it has the value we expect.
https://gist.github.com/marknagelberg/9fa2ff9679370cb0a088864ace29df89
We can take advantage of the work we did in Part 2 of the series using our application factory pattern to easily create a fixture for our application instance with our testing configuration options. The code below does this by creating an application instance with testing configuration and returning its test client (the test client provides a simple interface to the application where we can trigger requests application and track cookies).
https://gist.github.com/marknagelberg/ecd07825d53088492a29f248482e6a5e
Note that the part after the yield statement represents the “teardown” part of the test: this is where the application instance is removed when the tests are done running.
We also need to create a similar fixture for our database. The following code creates the database and initializes the data with create_all(), adds one Name “Mark” and then cleans up the database after the tests are complete.
https://gist.github.com/marknagelberg/1ca20b79e6bdf0931d9be3b869735958
Right now, when out user enters information into the app’s simple web form, the data is simply added to the database and nothing changes from the user’s perspective. To add some more interesting system tests, let’s add a little bit of additional functionality to our application: it will now print out a list of all the existing names in the database on the main page.
Finally, we add a few more tests to use all of our new fixtures, including tests to make sure our application instance exists and ensure the HTML output produced contains data we expect.
https://gist.github.com/marknagelberg/a1ec5be4825d4498bc7c3cdefb9d919f
(Note that “Mark” appears on the main page since this record was added to the database as part of the fixture.)
Now, in your main app directory, you can run your tests by simply typing “pytest” in the command line. The result for our code here should look like this:
The three dots ‘…’ indicate that there were three tests and they each passed (if a test failed, one of these dots appear as an F).
Aside: during the creation of this post, I was puzzled to see that my code was running in the flask production environment, despite my configuration and environment variables clearly indicating that I was in development. Turns out there is another environment variable that needs to be set called FLASK_ENV, which defaults to “production”, turning off debug mode in Flask and throwing a warning when you run your application on the Flask development server. To fix this, run `export FLASK_ENV=“development”` on the command line. Note that this must be set as an environment variable: adding it in config.py doesn’t work. I’ve updated this information in Part 2. For further information in the Flask documentation, see here.
Resources
https://www.patricksoftwareblog.com/testing-a-flask-application-using-pytest/
https://piotr.banaszkiewicz.org/blog/2014/02/22/how-to-bite-flask-sqlalchemy-and-pytest-all-at-once/