Whether you like it or not, you are faced with a barrage of decisions every day. Human beings are essentially decision machines, and the quality of your life hinges on these choices you make. The better you are at it, the better your life will be.
Some decisions are low stakes. Sometimes, the stakes are tremendous. What should I let my kids do? Where should I invest? Should I switch jobs? Should I ride my bike or take a car? Should I move to that neighbourhood? Should I reach out to the family member I haven’t talked to in ages? Should I cross the street?
It’s valuable to have a mental decision framework that guides you to increase your decision quality and decrease the stress of the process. It’s also valuable to be aware of some common decision-making traps to avoid.
The Framework
The mental framework I use for making decisions looks like this:
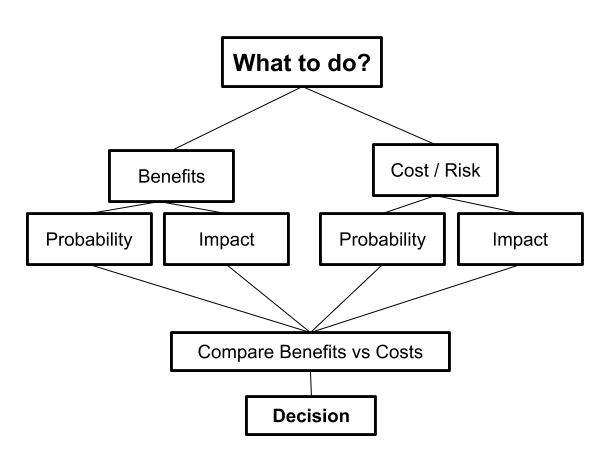
At the highest level, making a decision in this framework involves 3 steps:
- Estimate the benefits
- Estimate the costs
- If the benefits outweigh the costs, do it. If not, don’t. When you’re choosing between multiple courses of action, pick the one with the highest benefit-to-cost ratio
Steps #1 and #2 each break down into understanding two sub-components: probability and impact.
- Probability is the chance of the chance the benefit or cost happens
- Impact is how good the benefit is or how bad the cost is if it happens
Higher probability or higher impact means you should place more weight on that benefit or cost.
Most of us probably use a similar framework in our heads without even knowing it, but spelling it out like this helps clarify tough decisions and exposes hidden flaws in our decision-making.
5 Common Decision-Making Failures
This model may seem simple at first glance, but it’s deceptively tough to apply. This is because we’re human beings, not computers or all-knowing gods. We will never come close to applying this decision-making model perfectly. But even though we’ll never reach perfection, there are many ways to improve.
Here are five common failures you can keep an eye out for.
Common Failure #1: Loss aversion
Loss aversion means that we tend to hate losses much more than we love gains. As a result of this tendency, you irrationally underestimate benefits and overestimate costs in your decision-making.
This leads to particularly skewed decisions when considering benefits that are huge, but low probability (in other words, high payoff but a chance of a “loss”).
For example, say you’re applying for a big grant and you estimate your probability of getting it is less than 5%. Many would instantly choose to not write the grant without giving a second thought because the chances are slim. It’s true that winning the grant is unlikely, the payoff is huge. Applying might still be worthwhile and shouldn’t be dismissed without consideration.
Or consider Elon Musk. When he started SpaceX, he didn’t say “well, the chance of building a profitable, successful space company is low, so let’s just forget it”. Instead, he thought “the probability of success with this company is only about 10 percent, but the upside if I’m successful is tremendous so I’m going to try”.
Always remember that the emotional toll of losing is often irrationally high and doesn’t represent the actual cost of losing.
Common Failure #2: Not valuing your time
I remember in university, there was occasionally a “free pancake day”. Students would line up out the door for them, waiting about an hour in line to get these “free” pancakes.
The pancakes are only “free” if you don’t value your time, which is a huge mistake.
I personally believe you should value your time at least as high as your equivalent hourly salary at work. You may disagree with that number, but the point is that it’s absolutely worth something. This was one of the key takeaways from my economics background and probably the best piece of advice I can give.
Common Failure #3: Focusing only on money and measurable things
We often ignore benefits or costs that are not monetary, and in general we have a difficult time considering things that are not easy to measure. Here are some difficult-to-measure areas where there are often huge costs or benefits:
- Health and wellness (e.g “I could never ride a bicycle because it’s too dangerous”)
- Relationships with loved ones (e.g. cutting ties with a family member over a $100 dispute)
- Education, skills, and learning (e.g. “our company doesn’t have the skills to perform this core business task so let’s just contract it out”)
- Culture / morale (e.g. “We can’t fire Sarah. Sure, she’s a toxic, unethical person and makes everyone in the office miserable, but damn is she ever good at making widgets!”)
Common Failure #4: Not considering the costs of inaction
No matter what you do, you are making a decision. Choosing to not do anything or to “not make a decision” is itself a decision. As a result, the benefits and costs of inaction must be considered alongside the benefits and costs of all other courses of action.
Common Failure #5: Ignoring hidden benefits and costs
Many benefits and costs are commonly ignored because they are less obvious. For example:
- Transporting yourself by bicycle leads to improvements to your physical appearance, mood, strength, focus, and energy.
- Many people think the cost of owning a home is just a monthly mortgage payment. Hidden costs include property taxes, maintenance, and insurance, among many other expenses.
- Many people think the cost of driving a car is just the cost of gas. Hidden costs here include insurance, parking, and maintenance.
Keep an eye out for costs and benefits that may be lurking slightly under the surface.
Conclusion
Decisions are hard. You’ll never make perfect decisions, but if you have a solid mental framework at your side and have some awareness of common mistakes, you can get better. More importantly, you can relieve some stress and feel more confident that you’re doing the best you can with what you have.
If you want to commit this article to long-term memory, download the Anki deck I put together for it here.