Insights from Learning by Teaching Human Pupils and Teachable Agents: The Importance of Recursive Feedback by Sandra Okita and Daniel Schwartz.
Special thank-you to Andy Matuschak for pointing me to this paper.
You can download Roam Research Notes and an Anki flashcard deck I created for this research paper here.
Brief Overview of the Okita and Schwartz Paper
You have probably heard the advice that you should teach something if you really want to understand it. But does it really work, and if so, how?
Okita and Schwartz provide an extremely readable primer on the research behind Learning by Teaching and why it is so effective as a learning strategy.
They also explore a little-known benefit of learning by teaching called “recursive feedback” – feedback from watching your pupils use what you taught them. Using two separate experiments, Okita and Schwartz find that this special kind of feedback significantly improves teacher learning.
In this post, I summarize key insights from the paper on why learning by teaching works, and conclude with some thoughts on specific strategies for learning by teaching to improve your learning.
Why Learning by Teaching Works
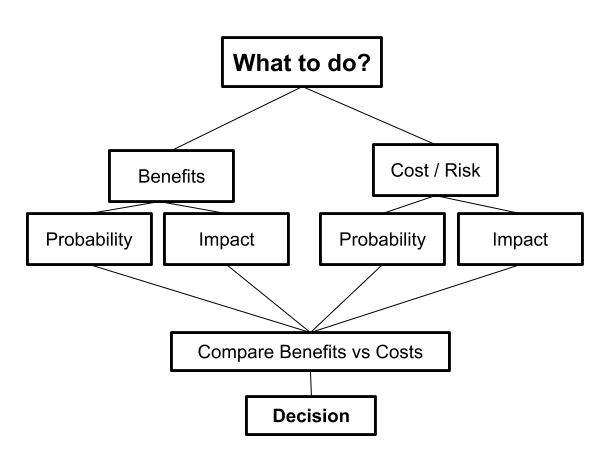
Okita and Schwartz divide the learning by teaching process into three distinct phases: preparation (the teacher’s preparations to teach), teaching (the actual act of teaching), and observation (when the teacher receives recursive feedback by seeing the student apply what they learned from the teacher). It turns out that each of these phases contribute to the teacher’s learning.
Preparing
Preparing to teach students helps teachers learn due to three main forces:
- Motivation: Preparation introduces strong emotions and motivation to truly understand the material and do it justice. This includes a sense of responsibility, the anticipation of a public performance, and a desire to avoid embarrassment or “looking stupid”.
- Generation: Preparing to teach involves a “generation effect“. The generation effect means that you remember information better when you generate it from your mind rather than passively reading it. Preparing to teach is generative because you have to frequently retrieve and elaborate on information from your memory as you think about how you are going to teach your students.
- Meta-cognitive vigilance: Meta-cognition refers to an awareness of your own thoughts. It turns out that preparing to teach generates this kind of awareness through the teacher’s self-explaining and self-generated questions as they anticipate the needs and questions of their pupils. This, in turn, helps teachers identify areas where they have conflicting knowledge or incomplete understanding.
Teaching
Three main aspects of this phase helps teachers learn:
- Explanation. The act of teaching involves explaining ideas to others. This leads to “explanation effects” that occur from explaining ideas rather than just receiving them.
- Question answering. Students often have questions of their teachers, which can reveal gaps in the teachers understanding or encourage the teacher to extend their understanding. In fact, Okita and Schwartz cite a study by Roscoe and Chi (2007) that found “tutees’ questions were responsible for about two-thirds of tutors’ reflective knowledge-building activity”.
- Physiological arousal. Anyone that has experienced public speaking knows that it is a very stimulating activity that focuses your mind. As you might expect, this kind of arousal and attention improves learning.
Observing
In this phase, the teacher receives recursive feedback by watching the student apply what they learned. You might think it’s obvious that feedback improves learning, but it turns out that’s not always the case.
For example, direct feedback, where a student tells a teacher directly how well they did, can be counterproductive because people often take this kind of feedback personally, leading to “self-handicapping, learned hopelessness, or social comparison”. When this happens, the recipient of the feedback tends to adopt attitudes like, “well, I guess I’m not the kind of person who’s good at math“. As a result, they give up or opt for an easier subject. As much as we all like to believe we would receive feedback objectively and use it to our advantage, our egos often get involved, whether we like it or not.
Thankfully, recursive feedback side-steps this issue. Since the teacher is not directly receiving feedback from the student, their egos are uninvolved. Instead, they see for themselves what worked and what didn’t. No one explicitly tells them, “this is where you need to improve, this is what you did wrong”. Okita and Schwartz note that this “creates an ego-protective buffer, because the pupil rather than the tutor takes the immediate responsibility for being wrong”.
I also believe recursive feedback helps build empathy skills. A lack of empathy, in my opinion, is often a major barrier to learning and self-improvement. Think of how many people you have encountered in schools or workplaces that have tried to explain something to you, but assume an unreasonable amount of knowledge, leave out critical bits of information, or explain things in ways that are otherwise unhelpful (e.g. using tons of jargon you’re unfamiliar with)? Often these people are very intelligent, and would be far more effective if they gained some empathy.
How can we use these lessons about Learning by Teaching to improve our own learning?
The main lesson I took away from the Okita and Schwartz paper is that Learning by Teaching is not just folk wisdom. It works. So, as learners, we should try to use it wherever we can. Here are some ideas:
- Develop a course or become a tutor. If there is a topic you really want to master, and you have enough time and resources, you can run an online or in-person course. In addition to the learning benefits, you can make some side income.
- Observe your students. To take advantage of recursive feedback, you need to be able to see your students apply their knowledge. Use tests, presentations, or projects to see what your students learned.
- Keep it interactive. Interaction with your students means more questions from them and, as a result, more learning for you. Okita and Schwartz note “Tutoring sessions should be arranged to limit the natural tendency of tutors to slip into didactics, which can eliminate opportunities for pupils to ask questions“. Students will often ask useful questions that help you better understand the material.
- Write online. Writing online is a form of teaching, whether it’s blog posts, twitter, email newsletters, or something else. It also provides ample opportunity to receive valuable feedback about your work.
- Develop a smart and interesting following. The quality of pupil questions impacts teacher learning. This means that, if you have an email list or a blog, or some other kind of online following, you learning would benefit from attracting high-quality people. Check out David Perell’s work on writing online, where he emphasizes the importance of writing for intelligent readers and leveraging their feedback to improve yourself.
- Encourage your students to keep in touch about the projects they work on and how they applied the knowledge you taught them. Your students will appreciate this, and you’ll also get valuable recursive feedback.
- Build things and watch people use what you’ve built. Okita and Schwartz point out that recursive feedback applies to areas other than Learning by Teaching. For example, producing products, tools, crafts, art, and then getting recursive feedback by observing how your “customer” uses it. One application of this idea that comes to mind is Agile software methodology, which relies on building software quickly, getting feedback on it as soon as possible, and constantly iterating and improving based on that feedback. If you produce something that others consume, you’ll gain by watching them use it.